 |
Top 10 Big Data platforms
May 19, 2025 | Editor: Michael Stromann
26
BigData platforms that allow to manage and analyze data sets so large and complex that it becomes difficult to process using traditional databases.
1

Snowflake is the only data platform built for the cloud for all your data & all your users. Learn more about our purpose-built SQL cloud data warehouse.
2
The most sophisticated, open search platform. Transform your data into actionable observability. Protect, investigate, and respond to complex threats by unifying the capabilities of SIEM, endpoint security, and cloud security.
3
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
4
Apache Spark is a fast and general engine for large-scale data processing. Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk. Write applications quickly in Java, Scala or Python. Combine SQL, streaming, and complex analytics.
5
The Apache Hive data warehouse software facilitates querying and managing large datasets residing in distributed storage. Hive provides a mechanism to project structure onto this data and query the data using a SQL-like language called HiveQL. At the same time this language also allows traditional map/reduce programmers to plug in their custom mappers and reducers when it is inconvenient or inefficient to express this logic in HiveQL.
6
Cloudera helps you become information-driven by leveraging the best of the open source community with the enterprise capabilities you need to succeed with Apache Hadoop in your organization. Designed specifically for mission-critical environments, Cloudera Enterprise includes CDH, the world’s most popular open source Hadoop-based platform, as well as advanced system management and data management tools plus dedicated support and community advocacy from our world-class team of Hadoop developers and experts. Cloudera is your partner on the path to big data.
7
Apache Cassandra is an open source distributed database management system designed to handle large amounts of data across many commodity servers, providing high availability with no single point of failure. Cassandra offers robust support for clusters spanning multiple datacenters, with asynchronous masterless replication allowing low latency operations for all clients.
8
Amazon Redshift is a fast, fully managed, petabyte-scale data warehouse service that makes it simple and cost-effective to efficiently analyze all your data using your existing business intelligence tools. You can start small for just $0.25 per hour with no commitments or upfront costs and scale to a petabyte or more for $1,000 per terabyte per year, less than a tenth of most other data warehousing solutions.
9
Teradata Aster features Teradata Aster SQL-GR analytic engine which is a native graph processing engine for Graph Analysis across big data sets. Using this next generation analytic engine, organizations can easily solve complex business problems such as social network/influencer analysis, fraud detection, supply chain management, network analysis and threat detection, and money laundering.
10
Unified Data Analytics Platform - One cloud platform for massive scale data engineering and collaborative data science.
11
Amazon EMR is a service that uses Apache Spark and Hadoop, open-source frameworks, to quickly & cost-effectively process and analyze vast amounts of data.
12
Presto is a highly parallel and distributed query engine for big data, that is built from the ground up for efficient, low latency analytics.
13

BigQuery is a serverless, highly-scalable, and cost-effective cloud data warehouse with an in-memory BI Engine and AI Platform built in.
15
HDInsight is a Hadoop distribution powered by the cloud. This means HDInsight was architected to handle any amount of data, scaling from terabytes to petabytes on demand. You can spin up any number of nodes at anytime. We charge only for the compute and storage you actually use.
16
Vertica offers organizations new and faster ways to store, explore and serve more data. Vertica lets organizations store data in a cost-effectively, explore it quickly and leverage well-known SQL-based tools to get customer insights. By offering blazingly-fast speed, accuracy and security, it offers operational advantages to the entire organization.
17
Schema-free SQL Query Engine for Hadoop, NoSQL and Cloud Storage. Get faster insights without the overhead (data loading, schema creation and maintenance, transformations, etc.). Analyze the multi-structured and nested data in non-relational datastores directly without transforming or restricting the data
18
Qubole is a Big Data as a Service (BDaas) Platform Running on Leading Cloud Offerings Like AWS. Qubole enables you to utilize a variety of Cloud Databases and Sources, including S3, MySQL, Postgres, Oracle, RedShift, MongoDB, Vertica, Omniture, Google Analytics, and your on-premise data
19

The MapR Distribution for Apache Hadoop provides organizations with an enterprise-grade distributed data platform to reliably store and process big data. MapR packages a broad set of Apache open source ecosystem projects enabling batch, interactive, or real-time applications. The data platform and the projects are all tied together through an advanced management console to monitor and manage the entire system.
20
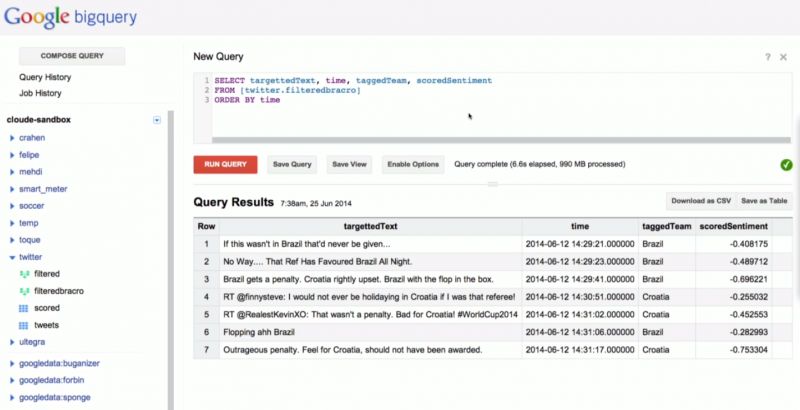
Build, deploy, and run data processing pipelines that scale to solve your key business challenges. Google Cloud Dataflow enables reliable execution for large scale data processing scenarios such as ETL, analytics, real-time computation, and process orchestration.
21
Google Cloud Dataproc is a managed Hadoop MapReduce, Spark, Pig, and Hive service designed to easily and cost effectively process big datasets. You can quickly create managed clusters of any size and turn them off when you are finished, so you only pay for what you need. Cloud Dataproc is integrated across several Google Cloud Platform products, so you have access to a simple, powerful, and complete data processing platform.
22
SAP HANA converges database and application platform capabilities in-memory to transform transactions, analytics, text analysis, predictive and spatial processing so businesses can operate in real-time.
23
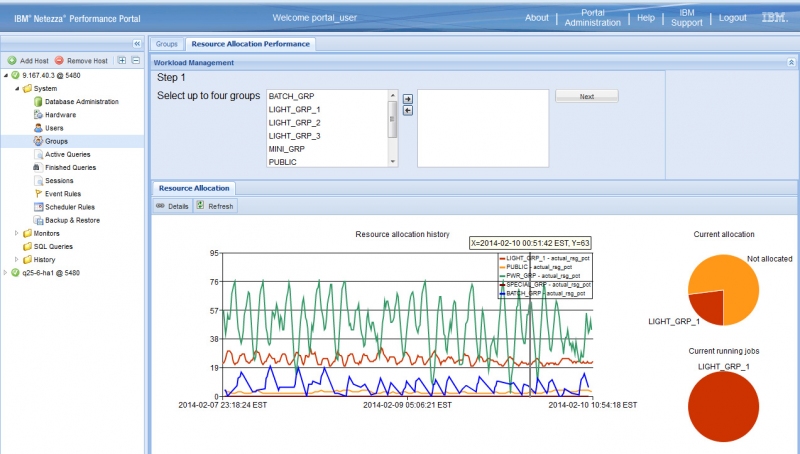
IBM Netezza appliances - expert integrated systems with built in expertise, integration by design and a simplified user experience. With simple deployment, out-of-the-box optimization, no tuning and minimal on-going maintenance, the IBM PureData System for Analytics has the industry’s fastest time-to-value and lowest total-cost-of-ownership.
24
1010data provides a cloud-based platform for big data discovery and data sharing that delivers actionable, data-driven insights quickly and easily. 1010data offers a complete suite of products for big data discovery and data sharing for both business and technical users. Companies look to 1010data to help them become data-driven enterprises.
Important news about Big Data platforms
2025. Snowflake Cortex AI now features native multimodal AI capabilities
Snowflake has introduced Cortex AI COMPLETE Multimodal, the major enhancement that brings the power to analyze images and other unstructured data directly into Snowflake’s query engine, using familiar SQL at scale. It allows to unify your structured and unstructured data more efficiently and with less complexity. It works seamlessly across Snowflake data, Iceberg tables and object storage like Amazon S3 — all without moving your data. You can also leverage Snowflake’s built-in security and governance to generate deeper, trusted insights across all types of enterprise data.
2022. Cloudera launches its all-in-one SaaS data lakehouse
Cloudera, the Hadoop-focused big data company, is now concentrating on becoming the unified data fabric for hybrid data platforms. The company has taken a significant step in this direction with the launch of its Cloudera Data Platform (CDP) One data lakehouse as a service (LaaS). This managed solution is designed to provide enterprises with a platform that facilitates self-service analytics and data access for a broader range of employees. The company refers to it as the “first all-in-one data lakehouse SaaS offering,” although Databricks, which popularized the lakehouse concept, also provides SaaS-based solutions. While it makes for compelling marketing, Cloudera contends that its service is the first to integrate compute, storage, ML, streaming analytics and enterprise security.
2021. Firebolt raises $127M for its new approach to cheaper and more efficient big data analytics

In the vast, uncharted galaxies of corporate data, where most companies flounder through the cosmos in search of answers to life, the universe, and everything related to data warehousing, Snowflake once appeared as the proverbial whale of enlightenment. Yet now, along comes Firebolt, a plucky little startup with dreams of disrupting the disruptor, waving around an eyebrow-raising $127 million in Series B funding. Firebolt boldly claims it’s up to 182 times faster than other data warehouses — which sounds preposterous, until you realize they've actually based this marvel on obscure academic research that no one else had thought to apply, involving astonishingly nimble feats of data compression and parsing wizardry. In short, Firebolt promises not only to connect data lakes with a vast data ecosystem but also to make them light as a feather, needing only a fraction of the cloud capacity. And naturally, fewer bits mean fewer bucks.
2020. Panoply raises $10M for its cloud data platform
Panoply, a platform that simplifies setting up a data warehouse and analyzing that data with standard SQL queries, has secured $10 million in funding. The company, which was established in 2015, has largely adhered to its initial vision of democratizing access to data warehousing and the associated analytics capabilities. In recent years, it has also developed additional code-free data integrations into the platform, making it easier for businesses to gather data from a broad range of sources, including Salesforce, HubSpot, NetSuite, Xero, QuickBooks, Freshworks and others. It also integrates with other data warehousing services like Google’s BigQuery and Amazon’s Redshift, as well as all major BI and analytics tools.
2020. Altinity grabs $4M to build cloud version of ClickHouse open-source data warehouse
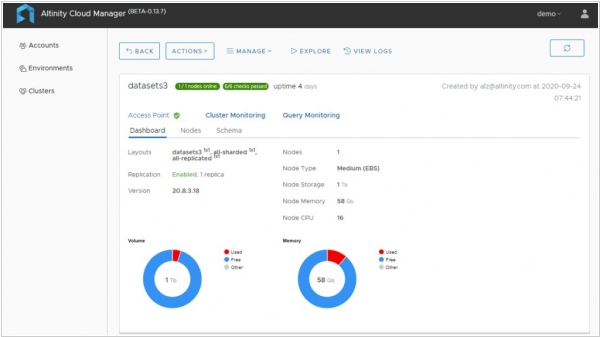
Altinity, the rather clever and somewhat commercial brains behind the open-source wonder that is ClickHouse data warehouse, has just announced that it’s managed to nab a nifty $4 million seed round, which, quite naturally, it’s putting to use on something delightfully grand: Altinity.Cloud. Now, Altinity.Cloud is no ordinary cloud service. No, indeed not. It’s an expressway to production-ready ClickHouse clusters, complete with a dedicated team of boffins standing by, ready to hold your hand through every thrilling (and occasionally befuddling) twist of the application lifecycle. Whether you're on the brink of brilliance in app design or bravely paddling through the depths of production, Altinity.Cloud isn’t just a cloud service—oh no—it’s the full consulting wizardry wrapped in a virtual bow.
2020. InfoSum raises $15.1M for its privacy-first, federated approach to big data analytics
InfoSum, a London-based startup that has developed a method for organizations to exchange their data without directly sharing it — through a federated, decentralized framework that uses mathematical models to organize, “read,” and query the data — is announcing today that it has secured $15.1 million in funding. InfoSum’s solution, while currently focused on marketing technology, has implications for various industries. The choice to concentrate on martech was partly due to the fact that Halstead had the most experience working in this sector at DataSift, although the intention is to expand into other fields as well.
2020. Collibra nabs $112.5M for its big data management platform
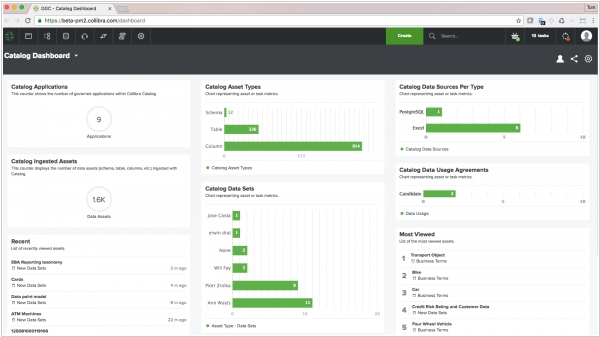
Collibra, which offers solutions for managing, storing and analyzing large datasets, has secured $112.5M in Series F funding, reaching a valuation of $2.3 billion. Collibra began as a spin-off from Vrije Universiteit in Brussels, Belgium and now collaborates with around 450 enterprises and other major organizations. Its clients include Adobe, Verizon, insurers AXA and several healthcare providers. The company's offerings span various services related to organizational data, including tools to assist customers in complying with local data protection regulations and securely storing data, as well as tools (and plug-ins) for running analytics and more.
2020. BackboneAI scores $4.7M seed to bring order to intercompany data sharing

It is a truth universally acknowledged—at least by those wrangling the universe’s ceaseless torrents of data—that something like BackboneAI was bound to pop into existence. And pop it has, with the elegance of a quantum sneeze, announcing a tidy $4.7 million seed investment to fuel its mission. The early-stage startup is here to rescue companies drowning in external data deluges, offering an AI platform that does for data what hyper-intelligent intergalactic beings do for bureaucracy: automate it with flair. Whether it’s keeping absurdly complex data catalogues in sync, orchestrating the bewildering ballet of construction materials between firms, or untangling the legal spaghetti of entertainment content rights, BackboneAI is ready to ensure that the data flows, and flows beautifully, in every conceivable dimension.
2019. Starburst raises $22M to modernize data analytics with Presto

Starburst, the company aiming to commercialize the open-source Presto distributed query engine for big data (originally created at Facebook), has revealed that it has secured a $22 million funding round. The primary concept behind Presto is to enable anyone to use the standard SQL query language to perform interactive queries on large datasets that can reside across various sources. Starburst intends to monetize Presto by introducing several enterprise-focused features, with a key emphasis on security, such as role-based access control, along with connectors to enterprise systems like Teradata, Snowflake and DB2 and a management dashboard where users can, for example, configure the cluster to auto-scale.
2019. HPE acquires big data platform MapR

Hewlett Packard Enterprises has acquired MapR Technologies, the provider of a Hadoop-based data analytics platform. The acquisition encompasses MapR’s technology, intellectual property and expertise in AI, machine learning and data management. The MapR suite will enhance HPE’s existing big data solutions, which includes the BlueData software it purchased in November. BlueData’s software offers a container-based approach for deploying and managing Hadoop, Spark and other environments on bare metal, cloud, or hybrid platforms. The MapR platform delivers various capabilities for running distributed applications. The software provides storage APIs for the S3 API, along with APIs for HDFS, POSIX, NFS and Kafka.

